Abstract¶
The Notebook Aspect of the Rubin Science Platform is built on top of JupyterHub and JupyterLab, running inside Kubernetes. The Science Platform must create Kubernetes pods and associated resources for users on request, maintain internal state for which pods are running so that the user is directed to their existing pod if present, and shut down pods when requested, either by the user or the system. Creating a pod may also require privileged setup actions, such as creating a home directory for the user.
JupyterHub provides a Kubernetes spawner that can be used for this purpose, but it requires granting extensive Kubernetes permissions directly to JupyterHub, a complex piece of software that is directly exposed to user requests. This tech note proposes an alternative design using a JupyterHub spawner implementation that delegates all of its work to a RESTful web service. That service would act as a Kubernetes controller, managing user labs and associated Kubernetes resources, as well as associated Science Platform business logic such as user home directory creation, construction of the lab options form, and image pre-pulling. This same approach can be used for creating Dask pods for parallel computation within the Science Platform or other per-user container-based features,
Background¶
See DMTN-164 for a complete description of the v2 architecture of the Notebook Aspect of the Rubin Science Platform. This tech note only touches on aspects relevant to user lab pod creation.
The v2 architecture uses JupyterHub Kubernetes Spawner to spawn user pods for notebooks, with significant local customizations via hooks defined in the nublado2 package.
Those hooks create additional Kubernetes resources used by the pod: multiple ConfigMap resources with configuration, /etc/passwd and related files for username and group mappings inside the pod; and Kubernetes secrets (via vault-secrets-operator).
Each user pod and its associated resources are created in a per-user namespace.
In addition, to support a proof-of-concept Dask integration, the initial implementation creates a ServiceAccount, Role, and RoleBinding for the user to allow them to create pods in their namespace.
The Kubernetes installation of JupyterHub in this architecture uses Helm and the Zero to JupyterHub Helm chart.
Configuration for the spawner is injected through the Helm chart and a custom ConfigMap resource.
The list of resources to create in each user namespace when creating a lab pod is specified in the Helm configuration as Jinja templates, which are processed during lab creation by the custom spawner hooks.
This system is supported by two ancillary web services. moneypenny is called before each pod creation to provision the user if necessary. Currently, the only thing that it does is create user home directories in deployments where this must be done before the first pod creation. This design is described in SQR-052.
Second, since the images used for user notebook pods are quite large, we prepull those images to each node in the Kubernetes cluster. This is done by cachemachine. The cachemachine web service is also responsible for determining the current recommended lab image and decoding the available image tags into a human-readable form for display in the lab creation menu.
Problems¶
We’ve encountered several problems with this approach over the past year.
The current Dask proof-of-concept grants the user creation permissions in Kubernetes to create pods. Since pod security policies or an admission controller are not implemented on Science Platform deployments, this allows users to create privileged pods and mount arbitrary file systems, thus bypassing security permissions in the cluster and potentially compromising the security of the cluster itself via a privileged pod.
Allowing JupyterHub itself to create the pods requires granting extensive Kubernetes permissions to JupyterHub, including full access to create and execute arbitrary code inside pods, full access to secrets, and full access to roles and role bindings. Worse, because each user is isolated in their own namespace, JupyterHub has to have those permissions globally for the entire Kubernetes cluster. While JupyterHub itself is a privileged component of the Science Platform, it’s a complex, user-facing component and good privilege isolation practices argue against granting it such a broad set of permissions. A compromise of JupyterHub currently means a complete compromise of the Kubernetes cluster and all of its secrets.
Creation of the additional Kubernetes resources via hooks is complex and has been error-prone. We’ve had multiple problems with race conditions where not all resources have been fully created (particularly the
Secretcorresponding to aVaultSecretand the token for the user’sServiceAccount) before the pod is created, resulting in confusing error messages and sometimes failure of the pod to start. The current approach also requires configuring the full list of resources to create in the values file for the Notebook Aspect service, which is awkward to maintain and override for different environments.JupyterHub sometimes does a poor job of tracking the state of user pods and has had intermittent problems starting them and shutting them down cleanly. These are hard to debug or remedy because the code is running inside hooks inside the Kubespawner add-on in the complex JupyterHub application.
The interrelated roles of the nublado2, moneypenny, and cachemachine Kubernetes services in the lab creation process is somewhat muddled and complex, and has led to problems debugging service issues. nublado2 problems sometimes turn out to be cachemachine problems or moneypenny problems but it’s not obvious that this is the case from the symptoms, error messages, or logs.
We have other cases where we would like to create pods in the Kubernetes environment with similar mounts and storage configuration to Notebook Aspect pods but without JuptyerHub integration, such as for privileged administrator actions in the cluster. Currently, we have to create these pods manually because the JupyterHub lab creation mechanism cannot be used independently of JupyterHub.
Proposed design¶
The proposed replacement design moves pod creation into a separate web service that acts as a Kubernetes controller. The spawner implementation in JupyterHub will be replaced with a thin client for that web service. The lab controller would subsume cachemachine and moneypenny and thus take over responsibility for prepulling images, constructing the lab creation options form based on knowledge of the available images, and performing any provisioning required for the user before starting their lab.
The lab controller API would also be available for non-JupyterHub pod creation, including Dask. This would replace the Kubernetes pod creation code in Dask Kubernetes.
As a result of those changes, all Kubernetes cluster permissions can be removed from both JupyterHub and the user lab pods. Instead, both JupyterHub and user pods (via Dask) would make requests to the lab controller, authenticated with either JupyterHub’s bot user credentials or the user’s notebook token. That authentication would be done via the normal Science Platform authentication and authorization system (see DMTN-234). The lab controller can then impose any necessary restrictions, checks, and verification required to ensure that only safe and expected pod creation operations are allowed.
Only the lab controller itself will have permissions on the Kubernetes cluster. It will be smaller, simpler code audited by Rubin Observatory with a very limited API exposed to users.
Inside JupyterHub, we would replace the KubeSpawner class with a RESTSpawner class whose implementation of all of the spawner methods is to make a web service call to the lab controller.
We can use the user’s own credentials to authenticate the lab creation call to the lab controller, which ensures that a compromised JupyterHub cannot create pods as arbitrary users.
Other calls can be authenticated with JupyterHub’s own token, since they may not be associated with a user request.
The lab controller will know which user it is creating a pod for, and will have access to the user’s metadata, so it can set quotas, limit images, set environment variables, and take other actions based on the user and Science Platform business logic without having to embed all of that logic into JupyterHub hooks.
Here is that architecture in diagram form.
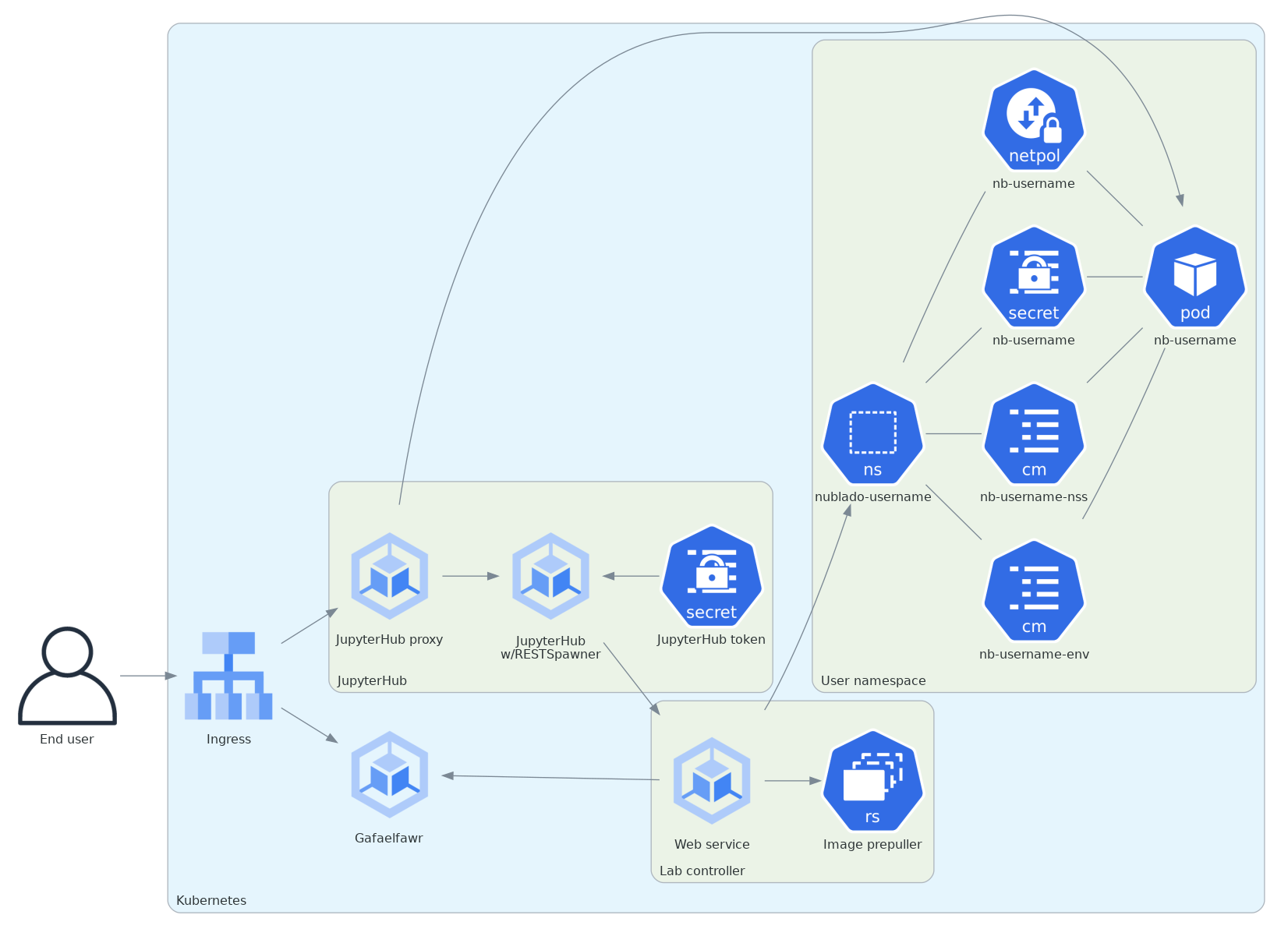
Figure 1 High-level structure of the JupyterHub architecture using an external lab controller. This diagram is somewhat simplified for clarity. The lab may also talk to the lab controller to manage Dask pods, JupyterHub and the lab talk over the internal JupyterHub protocol, and both JupyterHub and the lab talk to the lab controller via the ingress rather than directly.¶
Here is a sequence diagram of the new lab creation process.

Figure 2 Sequence of operations for lab creation. Authentication and authorization steps have been omitted for clarity.¶
The Dask pod creation process will look very similar, except that the request will be coming from the user’s lab and the Dask pods will be considered child pods of the lab pod. A shutdown request for the lab pod will also shut down all of the Dask pods.
Lab controller REST API¶
Initial routes for the lab creation API. This design makes the explicit assumption that a given user may only have one lab running at a time. Supporting multiple labs for the same user (something that is supported by JupyterHub but not by the current design of the Rubin Science Platform) would require a redesign of the API.
This API will be protected by the regular authentication mechanism for the Rubin Science Platform, described in DMTN-224.
It will use multiple ingresses to set different authentication requirements for different routes.
The POST /nublado/spawner/v1/labs/<username>/create route will request a delegated notebook token, which it will provide to the newly-created pod so that the user has authentication credentials inside their lab.
The admin:jupyterlab scope is a new scope granted only to the JupyterHub pod itself and (optionally) Science Platform administrators.
It controls access to APIs that only JupyterHub needs to use.
If Science Platform administrators need to test pod creation or see the event stream directly, they should use user impersonation (creating a token with the identity of the user that they’re debugging).
GET /nublado/spawner/v1/labsReturns a list of all users with running labs. Example:
["adam", "rra"]
Credential scopes required:
admin:jupyterlabGET /nublado/spawner/v1/labs/<username>Returns status of the lab pod for the given user, or 404 if that user has no running or pending lab. Example:
{ "username": "rra", "status": "running", "pod": "present", "internal_url": "http://nublado-rra/nb-rra:8888", "options": { "enable_debug": false, "image_list": "lsstsqre/sciplat-lab:w_2022_37", "reset_user_env": false, "size": "large" }, "env": { "JUPYTERHUB_API_URL": "http://hub.nublado2:8081/nb/hub/api" }, "uid": 4266950, "gid": 4266950, "groups": [ { "name": "lsst-data-management", "id": 170034 }, { "name": "rra", "id": 4266950 } ], "quotas": { "limits": { "cpu": 4, "memory": 12884901888 }, "requests": { "cpu": 4, "memory": 1073741824 } }, "events": [ { "event": "info", "data": "lab creation initiated for rra", "sent": false }, { "event": "progress", "data": "2" }, { "event": "complete", "data": "Operation complete for rra" } ] }
The response contains a mix of information provided at lab creation (options and env), information derived from the user’s identity used to create the lab (UID, GID, group membership), and information derived from other settings (the quotas, which are based primarily on the chosen size).
statusis one ofpending,running,terminating, orfailed, and corresponds to thephasefield of a Kubernetes PodStatus object.podis one ofpresentormissingand indicates the lab controller’s understanding of whether the corresponding Kubernetes pod exists. (This is relevant primarily for a lab infailedstatus.)internal_urlwill only be present for a pod withstatusequal torunningandpodequal topresentand will be a string representing the URL from which the Hub can access the Kubernetes pod. This URL is only valid within the Kubernetes cluster.events(see theGET /nublado/spawner/v1/labs/<username>/events) is a list of events for the current operation for the current user. These events will continue to be available until lab creation is attempted again for that user, or the lab controller restarts or garbage-collects old information.If lab creation for that user was attempted but failed, the record of that failure is retained with a
failedstatus. This data may be persisted in Redis; see Scaling.Credential scopes required:
admin:jupyterlabPOST /nublado/spawner/v1/labs/<username>/createCreate a new lab pod for a given user. Returns status 303 with a
Locationheader pointing to/nublado/spawner/v1/labs/<username>if creation of the lab pod has been successfully queued.This uses a separate route instead of a
PUTverb on the/nublado/spawner/v1/labs/<username>route because it needs separate Gafaelfawr configuration. (Specifically, it needs to request a delegated notebook token so that it can be provided to the newly-created lab.)This route returns as soon as the creation is queued. To monitor the status of the pod creation, use
GET /nublado/spawner/v1/labs/<username>/events.The body of the
POSTrequest is a specification for the lab. Example:{ "options": { "enable_debug": ["true"], "image_list": ["sciplat/sciplat-lab:w_2022_37"], "reset_user_env": ["true"], "size": ["large"] }, "env": { "JUPYTERHUB_API_URL": "http://hub.nublado2:8081/nb/hub/api" } }
The keys of the
optionsdictionary should be the parameters submitted by aPOSTof the form returned byGET /nublado/spawner/v1/lab-form/<username>. Theoptionsvalues may be normal strings and booleans, or they can be in the form returned by the JupyterHubSpawner.options_from_formmethod. In that case, all values are lists with one element, boolean values are the stringstrueorfalse, and numbers are the string representation of that number. The lab controller supports either format of input and will automatically convert the latter form to the former.The
envdictionary contains the environment variables that JupyterHub wants to pass to the lab. This dictionary will contain secrets, such as a token for the lab to talk back to JupyterHub.If a lab for the user already exists, this request will fail with a 409 status code. The configuration of the existing lab cannot be modified with a
POSTrequest. It must be deleted and recreated. If a lab exists in thefailedstatus, a new lab can be created for that user, and the old failure information from the previous lab will be discarded. When creating a new lab when one exists infailedstatus, ifpodispresent, the lab controller will attempt again to remove the old pod first.If there is no record of the lab having been created but the namespace already exists, the lab controller will stop any pod and delete the namespace first, and then recreate it fresh. This allows recovery from crashed lab controllers or crashed JupyterHub pods.
The caller must provide credentials for the user who will own the lab (generally, a delegated notebook token). JupyterHub cannot create labs for arbitrary users.
Credential scopes required:
exec:notebookGET /nublado/spawner/v1/labs/<username>/eventsReturns the events for the lab of the given user, suitable for display in the JupyterHub lab creation status page. This is a stream of server-sent events.
If the lab creation has completed (either because the lab is in
runningstatus or has failed), the server-sent events stream will be closed. Otherwise, it will stay open until the create or delete operation is complete. This can therefore be used by the JupyterHub spawner API to wait for completion of the start operation.The following event types are defined:
completeIndicates that the lab was successfully created. The
datafield must be present but contains no useful information.errorAn error or warning in the creation or deletion process. The
datafield will be a human-readable message.failedIndicates that lab creation has failed. The
datafield must be present but contains no useful information.infoAn informational message or a completion of a stage in the creation or deletion process. The
datafield will be a human-readable message.progressAn update to the progress bar. The
datafield will be the estimated completion percentage.
Successfully calling
POST /nublado/spawner/v1/labs/<username>/createorDELETE /nublado/spawner/v1/labs/<username>clears the previous saved event stream and starts a new event stream for that operation. Only one operation can be in progress at a time, and the event stream only represents the current operation.Credential scopes required:
exec:notebookDELETE /nublado/spawner/v1/labs/<username>Stop a running pod. Returns 202 on successful acceptance of the request and 404 if no lab for this username is currently running.
This puts the lab in
terminatingstate and starts the process of stopping it and deleting its associated resources. The progress of that termination can be retrieved fromGET /nublado/spawner/v1/labs/<username>/events.If termination is successful, the resource is removed. If termination is unsuccessful, the lab is put into a
failedstate and retained for error reporting.Credential scopes required:
admin:jupyterlabJupyterHub can delete labs without having the user’s credentials available, since this may be required to clean up state after an unclean restart of the service.GET /nublado/spawner/v1/lab-form/<username>Get the lab creation form for a particular user. The form may be customized for the user; for example, some images or lab sizes may only be available to certain users.
The result is
text/htmlsuitable for inclusion in the lab creation page of JupyterHub. It will define a form whose elements correspond to the keys of theoptionsparameter to thePOST /nublado/spawner/v1/labs/<username>/createcall used to create a new lab. Each parameter should be single-valued.JupyterHub cannot retrieve the lab creation form for arbitrary users, only for the user for whom it has a delegated token, since the identity of the token may be used to determine what options are available.
Credential scopes required:
exec:notebookGET /nublado/spawner/v1/user-statusGet the pod status for the authenticating user. If the user does not have a pod, returns 404.
This is identical to the
GET /nublado/spawner/v1/labs/<username>route except that it only requires theexec:notebookscope, so users can use it, and the username is implicitly the calling user. It allows a user to obtain status information for their own pod and may be used under the hood by the top-level UI for the Science Platform. (For example, the UI may change the Notebook Aspect portion of the page to indicate the user already has a running lab they can reconnect to, rather than indicating that the user can create a new lab.)Credential scopes required:
exec:notebook
The API to create Dask pods is not yet defined in detail, but will look very similar to the above API, except that it will use a resource nested under the lab.
For example, /nublado/spawner/v1/labs/<username>/dask-pool/<name>.
JupyterHub spawner class¶
As discussed above, using a separate lab controller requires replacing Kubespawner with a new spawner API implementation. Some of the required details will not be obvious until we try to implement it, but here is a sketch of how the required spawner methods can be implemented. This is based on the JupyterHub spawner documentation (which unfortunately is woefully incomplete at the time of this writing).
The spawner implementation will assume that the token element of the authentication state in JupyterHub contains the delegated authentication credentials for the user, and use them to authenticate to the lab controller.
options_formCalls
GET /nublado/spawner/v1/spawn-form/<username>, authenticated as the user, and returns the resulting HTML.startCalls
POST /nublado/spawner/v1/labs/<username>/create, and then waits for the lab to finish starting. The waiting is done viaGET /nublado/spawner/v1/labs/<username>/eventsand waiting for acompleteorfailedevent.The
optionsparameter in thePOSTbody is set to the return value of theoptions_from_formmethod (which is not overridden by this spawner implementation). Theenvparameter in thePOSTbody is set to the return value of theget_envmethod (which is not overridden by this spawner implementation). Be aware that the return value ofget_envcontains secrets, such as the token for the lab to talk back to the hub.Calling
startclears the events for that user. Then, while waiting, thestartcoroutine updates an internal data structure holding a list of events for that user. Each event should be an (undocumented) JupyterHub spawner progress event.{ "progress": 80, "message": "text", "html_message": "html_text" }
progressis a number out of 100 indicating percent completion.html_messageis optional and is used when rendering the message on a web page.This doesn’t exactly match the event stream provided by the lab controller. To convert, keep the last reported progress amount and update it when a
progressevent is received, without emitting a new event. Then add an event with the last-seen progress for anyinfoorerrorevents. Set internal state indicating that the operation is complete and then add a final event (with a progress of 100) upon seeing acompleteorfailureevent.These events are used in the implementation of the
progressmethod described below. The event data structure should be protected by a per-userasyncio.Conditionlock. Thestartmethod will acquire the lock on each event, update state as needed, and then if aninfo,error,complete, orfailureevent was received, callnotify_allon the condition to awaken any threads of execution waiting on the condition in theprogressmethod.stopCalls
DELETE /nublado/spawner/v1/labs/<username>to stop the user’s lab and wait for it to complete. As withstart, the waiting is done viaGET /nublado/spawner/v1/labs/<username>/eventsand waiting for acompleteorfailedevent.Calling
stopclears the events for that user. Then, while waiting, thestopcoroutine updates an internal data structure holding a list of events for that user, in exactly the same way asstart.pollCalls
GET /nublado/spawner/v1/labs/<username>to see if the user has a running lab. ReturnsNoneif the lab is inpending,running, orterminatingstate,0if it does not exist, and2if the lab pod is infailedstate.progressYields (as an async generator) the list of progress events accumulated by the previous
startorstopmethod call. Returns once internal state has marked the operation complete.This is implemented by taking a lock on the event list for this user, returning all of the accumulated events so far, ending the loop if the operation is complete, and if not, waiting on the per-user
asyncio.Conditionlock. Allprogresscalls for that user will then be woken up bystartorstopwhen there’s a new message, and can yield that message and then wait again if the operation is still not complete.get_state,load_state,clear_stateThis spawner implementation doesn’t truly require any state, but reportedly one has to store at least one key or JupyterHub thinks the lab doesn’t exist.
get_statewill therefore record the event information used byprogress(events, progress amount, and completion flag).load_statewill restore it, andclear_statewill clear it.
The mem_limit, mem_guarantee, cpu_limit, and cpu_guarantee configurables in the spawner class are ignored.
Quotas are set as appropriate in the lab controller based on metadata about the user and the chosen options on the lab creation form.
Similarly, the cmd and args configuration parameters to the spawner are ignored.
The lab controller will always start the JupyterLab single-user server.
Labs for bot users¶
In several cases, we want a service to be able to create a lab for a bot user. One example is mobu, which performs actions typical of a Science Platform user to look for errors or other problems. Another example is Times Square (also see SQR-062), which uses labs to render notebooks.
One option would be to allow such services to talk to the lab controller directly, bypassing the complex JupyterHub layer that doesn’t have a clean API for creating a lab. However, the individual labs default to using JupyterHub’s OpenID Connect server for authentication and assume they can talk to a hub for other purposes (idle culling, max age culling, etc.). mobu also wants to simulate what a user would do, and users create their labs via JupyterHub.
Instead, we will standardize on some supported options for the JupyterHub lab spawn endpoint (POST /nb/hub/spawn).
These options are sent, with only minor transformation by the spawner class, to the lab controller via POST /nublado/spawner/v1/labs/<username>/create in the options key, so this amounts to a guarantee about what options are recognized.
The promise is that, regardless of what the lab creation form looks like or what parameters will be submitted by a normal user interaction with the JupyterHub lab creation page, a POST request with only the following options will be a supported way to create a lab:
image_typeMay be one of
recommended,latest-weekly,latest-daily, orlatest-release. The corresponding image, as determined by the rules in SQR-059, will be used for the lab. See Prepulling configuration for more details. Either this orimage_tagmust be set.image_tagThe tag of the image to spawn. The repository and image name are given by the image configuration and cannot be changed here. Either this or
image_typemust be set. If both are set,image_tagtakes precedence.sizeThe size of image to create. This controls resource requests and limits on the created pod. May be one of
small,medium, orlarge. The definitions of those sizes is determined by lab controller configuration.
The lab form returned by the GET /nublado/spawner/v1/lab-form/<user> route may use some of these same parameters or may use completely different parameters.
The only guarantee is that a POST with only those parameters will suffice for creating a lab for a bot user.
Pod configuration¶
Each created user lab pod, and any Dask pods for that lab pod, will live in a per-user namespace.
The namespace will be called nublado-<username>.
When shutting down a lab, first the pod will be stopped and then the namespace will be deleted, cleaning up all other resources.
Resources in the namespace will be prefixed with nb-<username>-.
This allows for easier sorting in management displays such as Argo CD.
UID and GIDs¶
The lab pod container will always be run with the user’s UID and primary GID, as taken from the user identity information associated with their token. If privileged actions are needed, they will be done via a separate sidecar container. See User provisioning for more information.
The supplemental groups of the lab pod will be set to the list of all the GIDs of the user’s group, except for their primary GID. Group memberships in groups that do not have GIDs are ignored for the purposes of constructing the supplemental group list.
Environment¶
The environment of the lab pod is a combination of three sources of settings, here listed in the order in which they override each other.
The
envparameter to thePOST /nublado/spawner/v1/labs/<username>/spawncall used to create the lab. This in turn comes straight from JupyterHub.Settings added directly by the lab controller.
MEM_LIMIT,MEM_GUARANTEE,CPU_LIMIT, andCPU_GUARANTEEare set to match the quotas that it calculates based on the user identity and the requested image size. (This matches the default JupyterHub spawner behavior.)IMAGE_DIGESTandIMAGE_DESCRIPTIONwill be set to the digest and human-readable description of the chosen image. Other variables that control the behavior of the lab startup scripts may be set based on the options provided via thePOSTthat created the lab.Settings added via the lab controller configuration. The Helm chart for the lab controller will allow injection of environment variables that should always be set in a given Science Platform deployment. This includes, for example, deployment-specific URLs used for service discovery or environment variables used to configure access to remote resources.
The pod environment will be stored in a ConfigMap named nb-<username>-env and used as the default source for environment variables in the pod.
Since the lab controller is under control of both the Pod object and the ConfigMap object, all environment variables not from secrets will be stored in the ConfigMap instead of set directly in the Pod object.
This makes it easier for humans to understand the configuration.
User and group mappings¶
The Notebook Aspect of the Science Platform uses a POSIX file system as its primary data store. That means it uses numeric UIDs and GIDs for access control and to record ownership and creation information.
To provided the expected POSIX file system view from the Notebook Aspect, mappings of those UIDs and GIDs to human-readable usernames and group names must be provided.
The lab controller does this by generating /etc/passwd and /etc/group files and mounting them into the lab container over top of the files provided by the container image.
The base /etc/passwd and /etc/group files are whatever minimal files are required to make the container work and provide reasonable human-readable usernames and groups for files present in the container.
/etc/passwd as mounted in the container has one added entry for the user.
Their name, UID, and primary GID are taken from the user identity information associated with their token.
The home directory is always /home/<username> and the shell is always /bin/bash.
/etc/group as mounted in the container has an entry for each group in the user’s group membership that has an associated GID.
Groups without GIDs cannot be meaningfully represented in the /etc/group structure and are ignored.
The user is added as a supplementary member of the group unless the GID of the group matches the user’s primary GID.
No /etc/shadow or /etc/gshadow files are mounted in the pod.
The pod is always executed as the intended user and PAM should not be used or needed, so nothing should need or be able to read those files.
The /etc/passwd and /etc/group files will be stored under passwd and group keys in a ConfigMap named nb-<username>-nss (from Name Service Switch, the name of the Linux subsystem that provides this type of user and group information), and mounted via the Pod specification.
Mounts¶
The necessary volume mounts for a lab pod will be specified in the Helm configuration of the lab controller.
At the least, this will include a mount definition for /home, where user home directories must be located inside the pod.
Secrets¶
Each lab pod will have an associated Secret object named nb-<username> containing any required secrets.
It will have at least one key, token, which holds the notebook token for the user that is mounted into the pod and used to make API calls from the Notebook Aspect.
This token is obtained from the POST request that creates the lab, via the X-Auth-Request-Token header added by Gafaelfawr.
That route in the lab controller API will request a delegated notebook token.
Additional secrets may be added via the Helm configuration of the lab controller.
Each configured secret should be a reference to another Secret in the lab controller namespace and a key in that Secret object that should be added to the Secret object for each created pod.
The secrets will be copied into the created Secret object during pod creation.
One of those secrets may be tagged as a pull secret, in which case the required configuration to use it as a pull secret will also be added to the Pod specification.
Network policy¶
Prevention of direct connections from notebooks to other cluster services should be handled by the NetworkPolicy resources for those services.
However, for defense in depth, we will also install a NetworkPolicy for each lab pod.
This will restrict ingress to the JupyterHub proxy and, if necessary, the hub, and restrict egress to only non-cluster IP addresses plus the proxy, hub, and any Dask management interface that we may choose to create as a separate pod.
Non-cluster IP addresses may need to include other services outside of the Kubernetes cluster but still on private IP addresses, such as NFS servers, database servers, or object store endpoints.
Resource quotas¶
Since the lab controller can set resource limits and requests in the pod definition, separate ResourceQuota objects are not required in the normal case of a single lab pod.
However, when we support Dask, we may want to limit the total resources available to a user by using ResourceQuota objects in the Kubernetes namespace for that user.
Technically, this isn’t required, since the lab controller will be doing all Dask pod creation and could track quota usage internally.
Practically, though, it may be simpler and less effort to have Kubernetes track quotas and resource usage directly.
Argo CD support¶
All created resources will have the following annotations added:
argocd.argoproj.io/compare-options: "IgnoreExtraneous"
argocd.argoproj.io/sync-options: "Prune=false"
They will also have the following labels added:
argocd.argoproj.io/instance: "nublado-users"
This will cause all user resources created by the lab controller to appear under the Argo CD application nublado-users, which allows them to be explored and manipulated via the Argo CD UI even though they are not managed directly by Argo CD.
The drawback is that the nublado-users application will always display as “Progressing” because it contains unmanaged pods that are still running.
User provisioning¶
The lab controller will also take over from moneypenny the responsibility for doing initial user provisioning.
Instead of launching a separate pod and waiting for it to complete before starting the lab pod, user provisioning, if needed, will be done via an init container run as part of the same Pod object as the lab container.
If the lab controller is configured with a user provisioning container in its Helm chart, and it has not previously created a lab pod for a given user, it will add an init container to the Pod specification.
The specification for that container will be taken from its Helm configuration.
Once that pod has successfully been created (but not if it fails to start), the controller will mark that user as having been provisioned and will not add an init container for them in the future.
Init containers may still be run multiple times for a given user, since the lab controller may lose its records of which users have already been initialized when it is restarted. Therefore, any configured init container must be idempotent and safe to run repeatedly for the same user.
Decommissioning containers (for when a user is deleted) are not part of this specification and will not be supported initially. We may add them later if we discover a need.
Prepulling¶
The lab controller will also handle prepulling selected images onto all nodes in the cluster so that creating labs for the Notebook Aspect will be faster.
It does this by using the Kubernetes API to ask each node what images it has cached, and then creating a DaemonSet as needed to cache any images that are missing.
Configuration¶
The supported images for labs are configured via the Helm chart for the lab controller. The configuration of supported images controls what images are listed for selection in the lab creation form. It also doubles as the prepuller configuration. Only prepulled images (which should spawn within JupyterHub’s timeout) will be shown outside of the dropdown menu of all available tags.
An example of an image configuration:
images:
registry: registry.hub.docker.com
docker:
repository: lsstsqre/sciplat-lab
recommendedTag: recommended
numReleases: 1
numWeeklies: 2
numDailies: 3
This configuration pulls a group of images from the lsstsqre/sciplat-lab Docker image repository at registry.hub.docker.com that follow the tag conventions documented in SQR-059.
The latest release, the latest two weeklies, and the latest three dailies will be prepulled.
Whatever image has the tag recommended will appear as the first and default selected image.
Another example that uses Google Artifact Repository and explicitly pulls an image regardless of its recency:
images:
registry: us-central1-docker.pkg.dev
gar:
repository: sciplat
image: sciplat-lab
projectId: rubin-shared-services-71ec
location: us-central1
recommendedTag: recommended
numReleases: 1
numWeeklies: 2
numDailies: 3
pins:
- w_2022_22
- w_2022_04
This uses Google Artifact Registry as the source of containers instead of a Docker image repository compatible with the Docker Hub protocol. It also pins a specific image, ensuring that it is always pulled regardless of whether it is one of the latest releases, weeklies, or dailies.
Finally, here is an example for a Telescope and Site deployment that limits available images to those that implement a specific cycle:
images:
registry: ts-dockerhub.lsst.org
docker:
repository: sal-sciplat-lab
recommendedTag: recommended_c0026
numReleases: 0
numWeeklies: 3
numDailies: 2
cycle: 26
aliasTags:
- latest
- latest_daily
- latest_weekly
This is very similar to the first example but adds a cycle option that limits available images to those implementing that cycle.
It also includes an aliasTags option that lists tags that should be treated as aliases of other tags, rather than possible useful images in their own right.
REST API¶
To facilitate debugging of prepuller issues, there is a read-only REST API to see the status of a prepull configuration.
Changing the configuration requires changing the Helm chart or the generated ConfigMap object and restarting the lab controller.
All of these API calls require admin:jupyterlab scope.
GET /nublado/spawner/v1/imagesReturns information about the images available for spawning. Each keyword that is a valid value for
image_type(see Labs for bot users) is given first, with additional information about that image. Then, the keyallprovides a list of all known images.Example:
{ "recommended": { "reference": "<full Docker reference>", "tag": "<tag name>" "aliases": ["<tag name>", "<tag name>"], "name": "<human readable name>", "digest": "<image digest>", "prepulled": true }, "latest-weekly": { "reference": "<full Docker reference>", "tag": "<tag name>" "aliases": ["<tag name>", "<tag name>"], "name": "<human readable name>", "digest": "<image digest>", "prepulled": true }, "latest-daily": { "reference": "<full Docker reference>", "tag": "<tag name>" "aliases": ["<tag name>", "<tag name>"], "name": "<human readable name>", "digest": "<image digest>", "prepulled": true }, "latest-release": { "reference": "<full Docker reference>", "tag": "<tag name>" "aliases": ["<tag name>", "<tag name>"], "name": "<human readable name>", "digest": "<image digest>", "prepulled": true }, "all": [ { "reference": "<full Docker reference>", "tag": "<tag name>" "aliases": ["<tag name>", "<tag name>"], "digest": "<image digest>", "name": "<human readable name>", "prepulled": false } ] }
Each of the top-level object keys is the string literal exactly as shown. The alias information may not be complete. (In other words, the image may have additional aliases that are not shown.) Digest may be
nullif the image digest is not known (e.g. for an image that is only present on a remote Docker registry).GET /nublado/spawner/v1/prepullsReturns status of the known prepull configurations. The response is a JSON object with three keys.
The first key is
config, which contains the prepull configuration. This is identical to the configuration blocks given above, but converted to JSON and using snake-case instead of camel-case for keys.The second key is
images, which shows the list of images that are being prepulled as follows:"images": { "prepulled": [ { "reference": "<full Docker reference>", "tag": "<tag name>", "name": "<human readable name>", "digest": "<image digest>", "size": "<size in bytes>", "nodes": ["<node>", "<node>"] } ], "pending": [ { "reference": "<full Docker reference>", "tag": "<tag name>", "name": "<human readable name>" "digest": "<image digest>", "size": "<size in bytes>", "nodes": ["<node>", "<node>"], "missing": ["<node>", "<node>"] } ] }
prepulledlists the images that the lab controller believes have been successfully prepulled to every node based on this prepull configuration.pendinglists the ones that still need to be prepulled.sizemay or may not be present.For each image,
nodescontains a list of the nodes to which that image has been prepulled, andmissingcontains a list of the nodes that should have that image but do not.The third key is
nodes, which contains a list of nodes. Each node has the following structure:{ "name": "<name>", "eligible": true, "comment": "<why ineligible>", "cached": ["<reference>", "<reference>"] }
eligibleis a boolean saying whether this node is eligible for prepulling. If it is false, the reason for its ineligibility will be given incomment; otherwise,commentwill be missing.cachedis a list of images that are cached on that node.
Scaling¶
In the first version, there will be a single instance of the lab controller, which will manage its operations in memory. If the lab controller crashes or is restarted, any operations in progress will be aborted from the perspective of the controller. JupyterHub will assume the lab creation failed, and the user can re-attempt lab creation. At that point, the lab controller will clean up the leftover namespace and retry.
However, in the longer term, to support future scaling of the Science Platform and to avoid unnecessary outages during upgrades, we want the option of running multiple lab controller pods. This means that creation or deletion requests may start on one lab controller pod and then continue on a different controller pod.
Described here is a possible architecture to implement this, which we would tackle as subsequent work after the initial working version of the lab controller.
Storage¶
The specification for a pod and the event stream for pod creation and deletion may be requested from any instance of the lab controller. Controllers must therefore share that data, which implies some storage backend.
Redis seems ideal for this type of storage. The lab specification can be stored in a per-user Redis key. A Redis stream looks like the perfect data structure for storing events.
Each creation or deletion in progress needs one and only one instance of the lab controller to monitor its progress and update the information in Redis. We can use aioredlock to manage a lock for each user, which will be taken by an instance of the controller that is managing an operation for that user but will be released if that instance of the controller crashes.
The lab controller may also record in Redis the set of users for which it has already done provisioning, to avoid adding unnecessary init containers.
Restarting¶
If the controller managing an operation for a user exits, another controller has to pick up that operation and manage it, including monitoring Kubernetes for events and adding them to the event stream and updating the status once lab creation has completed. To achieve that:
Store a flag in Redis indicating whether an operation for a given user is in progress. Create this flag when starting to manage an operation, and delete it when the operation is complete.
On startup, and on some interval, look for all instances of that flag in Redis. For each, check to see if that user is already locked. If not, acquire the lock and start managing the operation. This will require examining Kubernetes to determine the status of the operation (for example, resources may be only partly created), and then resuming any Kubernetes watches.
Refresh the lock periodically as long as the instance is still running and managing an operation for that user.
If the instance managing an operation crashes, the lock will eventually time out, and the next instance to poll for pending unmanaged operations will locate that operation and resume it.
Future work¶
The API and Python implementation for Dask pod creation has not yet been designed. This will require new routes for creating and deleting Dask pods under the route for the user’s lab, and a way to get configuration information such as the user’s quota of Dask pods or the CPU and memory quotas of each pod. All Dask pods should be automatically deleted when the user’s lab is deleted.
The lab controller should also support launching privileged pods for administrative maintenance outside of the Notebook Aspect. This will require a new API protected by a different scope, not
admin:jupyterlab, since JupyterHub should not have access to create such pods.A more detailed specification of the configuration for provisioning init containers should be added, either here or (preferably) in operational documentation once this lab controller has been implemented.
The routes to return information about pods and prepull configurations are likely to need more detail. The draft REST API specifications in this document should be moved into code and replaced with documentation generated by OpenAPI, similar to what was done for Gafaelfawr.